5.3 Remote Procedure Call
A common pattern of communication used by application programs structured as a client/server pair is the request/reply message transaction: A client sends a request message to a server, and the server responds with a reply message, with the client blocking (suspending execution) to wait for the reply. Figure 137 illustrates the basic interaction between the client and server in such an exchange.
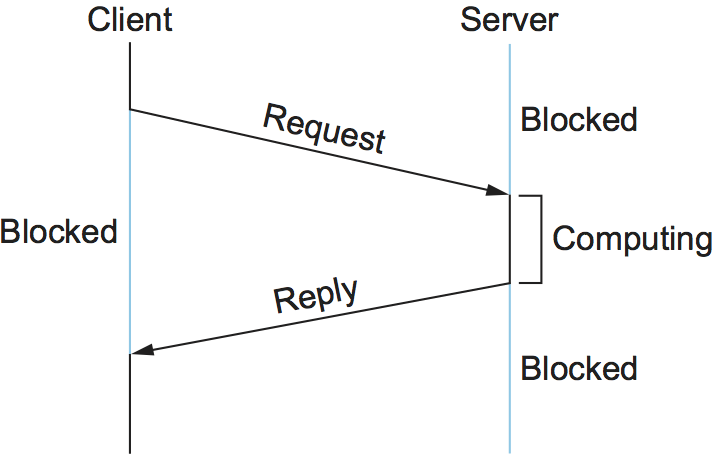
Figure 137. Timeline for RPC.
A transport protocol that supports the request/reply paradigm is much more than a UDP message going in one direction followed by a UDP message going in the other direction. It needs to deal with correctly identifying processes on remote hosts and correlating requests with responses. It may also need to overcome some or all of the limitations of the underlying network outlined in the problem statement at the beginning of this chapter. While TCP overcomes these limitations by providing a reliable byte-stream service, it doesn’t perfectly match the request/reply paradigm either. This section describes a third category of transport protocol, called Remote Procedure Call (RPC), that more closely matches the needs of an application involved in a request/reply message exchange.
5.3.1 RPC Fundamentals
RPC is not technically a protocol—it is better thought of as a general mechanism for structuring distributed systems. RPC is popular because it is based on the semantics of a local procedure call—the application program makes a call into a procedure without regard for whether it is local or remote and blocks until the call returns. An application developer can be largely unaware of whether the procedure is local or remote, simplifying his task considerably. When the procedures being called are actually methods of remote objects in an object-oriented language, RPC is known as remote method invocation (RMI). While the RPC concept is simple, there are two main problems that make it more complicated than local procedure calls:
The network between the calling process and the called process has much more complex properties than the backplane of a computer. For example, it is likely to limit message sizes and has a tendency to lose and reorder messages.
The computers on which the calling and called processes run may have significantly different architectures and data representation formats.
Thus, a complete RPC mechanism actually involves two major components:
A protocol that manages the messages sent between the client and the server processes and that deals with the potentially undesirable properties of the underlying network.
Programming language and compiler support to package the arguments into a request message on the client machine and then to translate this message back into the arguments on the server machine, and likewise with the return value (this piece of the RPC mechanism is usually called a stub compiler).
Figure 138 schematically depicts what happens when a client invokes a remote procedure. First, the client calls a local stub for the procedure, passing it the arguments required by the procedure. This stub hides the fact that the procedure is remote by translating the arguments into a request message and then invoking an RPC protocol to send the request message to the server machine. At the server, the RPC protocol delivers the request message to the server stub, which translates it into the arguments to the procedure and then calls the local procedure. After the server procedure completes, it returns in a reply message that it hands off to the RPC protocol for transmission back to the client. The RPC protocol on the client passes this message up to the client stub, which translates it into a return value that it returns to the client program.
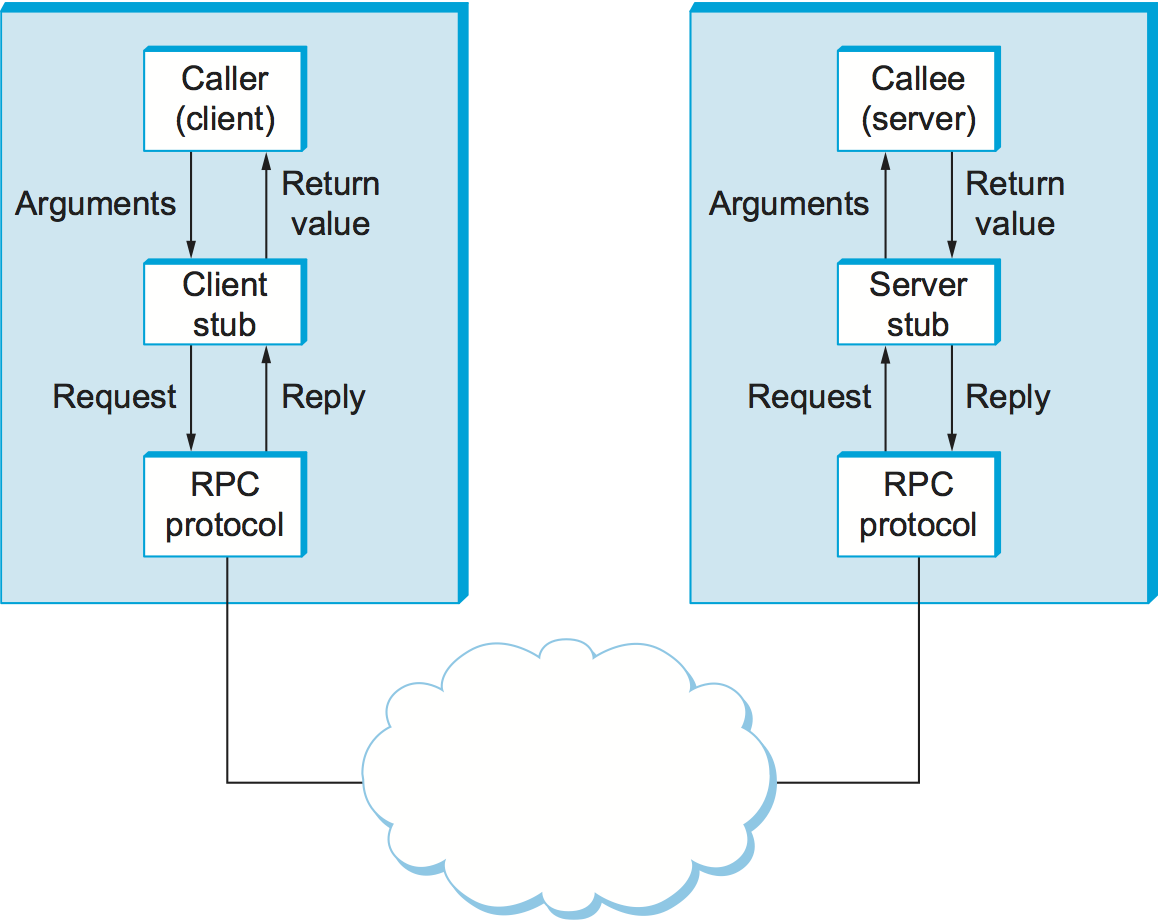
Figure 138. Complete RPC mechanism.
This section considers just the protocol-related aspects of an RPC mechanism. That is, it ignores the stubs and focuses instead on the RPC protocol, sometimes referred to as a request/reply protocol, that transmits messages between client and server. The transformation of arguments into messages and vice versa is covered elsewhere. It is also important to keep in mind that the client and server programs are written in some programming language, meaning that a given RPC mechanism might support Python stubs, Java stubs, GoLang stubs, and so on, each of which includes language-specific idioms for how procedures are invoked.
The term RPC refers to a type of protocol rather than a specific standard like TCP, so specific RPC protocols vary in the functions they perform. And, unlike TCP, which is the dominant reliable byte-stream protocol, there is no one dominant RPC protocol. Thus, in this section we will talk more about alternative design choices than previously.
Identifiers in RPC
Two functions that must be performed by any RPC protocol are:
Provide a name space for uniquely identifying the procedure to be called.
Match each reply message to the corresponding request message.
The first problem has some similarities to the problem of identifying nodes in a network (something IP addresses do, for example). One of the design choices when identifying things is whether to make this name space flat or hierarchical. A flat name space would simply assign a unique, unstructured identifier (e.g., an integer) to each procedure, and this number would be carried in a single field in an RPC request message. This would require some kind of central coordination to avoid assigning the same procedure number to two different procedures. Alternatively, the protocol could implement a hierarchical name space, analogous to that used for file pathnames, which requires only that a file’s “basename” be unique within its directory. This approach potentially simplifies the job of ensuring uniqueness of procedure names. A hierarchical name space for RPC could be implemented by defining a set of fields in the request message format, one for each level of naming in, say, a two- or three-level hierarchical name space.
The key to matching a reply message to the corresponding request is to uniquely identify request-replies pairs using a message ID field. A reply message had its message ID field set to the same value as the request message. When the client RPC module receives the reply, it uses the message ID to search for the corresponding outstanding request. To make the RPC transaction appear like a local procedure call to the caller, the caller is blocked until the reply message is received. When the reply is received, the blocked caller is identified based on the request number in the reply, the remote procedure’s return value is obtained from the reply, and the caller is unblocked so that it can return with that return value.
One of the recurrent challenges in RPC is dealing with unexpected responses, and we see this with message IDs. For example, consider the following pathological (but realistic) situation. A client machine sends a request message with a message ID of 0, then crashes and reboots, and then sends an unrelated request message, also with a message ID of 0. The server may not have been aware that the client crashed and rebooted and, upon seeing a request message with a message ID of 0, acknowledges it and discards it as a duplicate. The client never gets a response to the request.
One way to eliminate this problem is to use a boot ID. A machine’s boot ID is a number that is incremented each time the machine reboots; this number is read from nonvolatile storage (e.g., a disk or flash drive), incremented, and written back to the storage device during the machine’s start-up procedure. This number is then put in every message sent by that host. If a message is received with an old message ID but a new boot ID, it is recognized as a new message. In effect, the message ID and boot ID combine to form a unique ID for each transaction.
Overcoming Network Limitations
RPC protocols often perform additional functions to deal with the fact that networks are not perfect channels. Two such functions are:
Provide reliable message delivery
Support large message sizes through fragmentation and reassembly
An RPC protocol might “define this problem away” by choosing to run on top of a reliable protocol like TCP, but in many cases, the RCP protocol implements its own reliable message delivery layer on top of an unreliable substrate (e.g., UDP/IP). Such an RPC protocol would likely implement reliability using acknowledgments and timeouts, similarly to TCP.
The basic algorithm is straightforward, as illustrated by the timeline given in Figure 139. The client sends a request message and the server acknowledges it. Then, after executing the procedure, the server sends a reply message and the client acknowledges the reply.
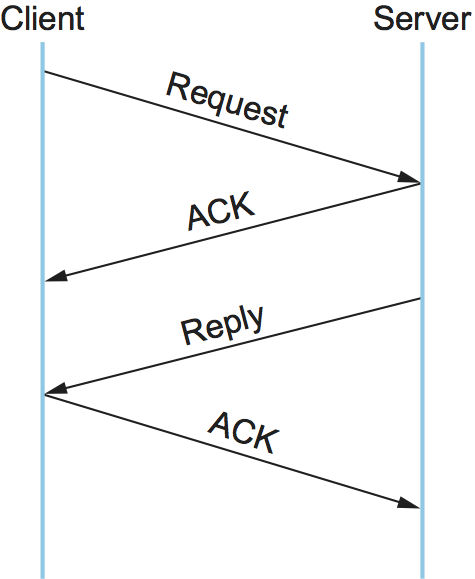
Figure 139. Simple timeline for a reliable RPC protocol.
Either a message carrying data (a request message or a reply message) or the ACK sent to acknowledge that message may be lost in the network. To account for this possibility, both client and server save a copy of each message they send until an ACK for it has arrived. Each side also sets a RETRANSMIT timer and resends the message should this timer expire. Both sides reset this timer and try again some agreed-upon number of times before giving up and freeing the message.
If an RPC client receives a reply message, clearly the corresponding request message must have been received by the server. Hence, the reply message itself is an implicit acknowledgment, and any additional acknowledgment from the server is not logically necessary. Similarly, a request message could implicitly acknowledge the preceding reply message—assuming the protocol makes request-reply transactions sequential, so that one transaction must complete before the next begins. Unfortunately, this sequentiality would severely limit RPC performance.
A way out of this predicament is for the RPC protocol to implement a channel abstraction. Within a given channel, request/reply transactions are sequential—there can be only one transaction active on a given channel at any given time—but there can be multiple channels. Or said another way, the channel abstraction makes it possible to multiplex multiple RPC request/reply transactions between a client/server pair.
Each message includes a channel ID field to indicate which channel the message belongs to. A request message in a given channel would implicitly acknowledge the previous reply in that channel, if it hadn’t already been acknowledged. An application program can open multiple channels to a server if it wants to have more than one request/reply transaction between them at the same time (the application would need multiple threads). As illustrated in Figure 140, the reply message serves to acknowledge the request message, and a subsequent request acknowledges the preceding reply. Note that we saw a very similar approach—called concurrent logical channels—in an earlier section as a way to improve on the performance of a stop-and-wait reliability mechanism.
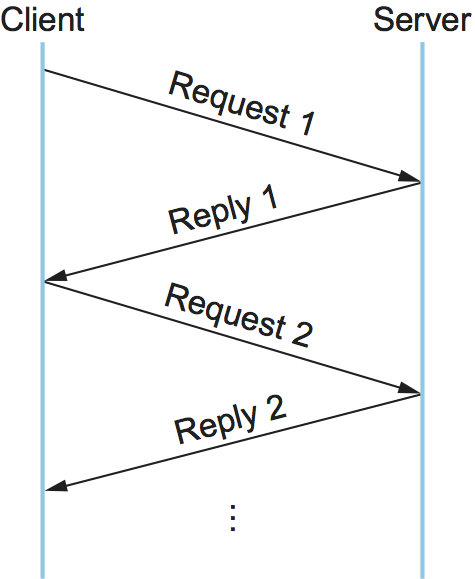
Figure 140. Timeline for a reliable RPC protocol using implicit acknowledgment.
Another complication that RPC must address is that the server may take an arbitrarily long time to produce the result, and, worse yet, it may crash before generating the reply. Keep in mind that we are talking about the period of time after the server has acknowledged the request but before it has sent the reply. To help the client distinguish between a slow server and a dead server, the RPC’s client side can periodically send an “Are you alive?” message to the server, and the server side responds with an ACK. Alternatively, the server could send “I am still alive” messages to the client without the client having first solicited them. The approach is more scalable because it puts more of the per-client burden (managing the timeout timer) on the clients.
RPC reliability may include the property known as at-most-once semantics. This means that for every request message that the client sends, at most one copy of that message is delivered to the server. Each time the client calls a remote procedure, that procedure is invoked at most one time on the server machine. We say “at most once” rather than “exactly once” because it is always possible that either the network or the server machine has failed, making it impossible to deliver even one copy of the request message.
To implement at-most-once semantics, RPC on the server side must recognize duplicate requests (and ignore them), even if it has already successfully replied to the original request. Hence, it must maintain some state information that identifies past requests. One approach is to identify requests using sequence numbers, so a server need only remember the most recent sequence number. Unfortunately, this would limit an RPC to one outstanding request (to a given server) at a time, since one request must be completed before the request with the next sequence number can be transmitted. Once again, channels provide a solution. The server could recognize duplicate requests by remembering the current sequence number for each channel, without limiting the client to one request at a time.
As obvious as at-most-once sounds, not all RPC protocols support this behavior. Some support a semantics that is facetiously called zero-or-more semantics; that is, each invocation on a client results in the remote procedure being invoked zero or more times. It is not difficult to understand how this would cause problems for a remote procedure that changed some local state variable (e.g., incremented a counter) or that had some externally visible side effect (e.g., launched a missile) each time it was invoked. On the other hand, if the remote procedure being invoked is idempotent—multiple invocations have the same effect as just one—then the RPC mechanism need not support at-most-once semantics; a simpler (possibly faster) implementation will suffice.
As was the case with reliability, the two reasons why an RPC protocol might implement message fragmentation and reassembly are that it is not provided by the underlying protocol stack or that it can be implemented more efficiently by the RPC protocol. Consider the case where RPC is implemented on top of UDP/IP and relies on IP for fragmentation and reassembly. If even one fragment of a message fails to arrive within a certain amount of time, IP discards the fragments that did arrive and the message is effectively lost. Eventually, the RPC protocol (assuming it implements reliability) would time out and retransmit the message. In contrast, consider an RPC protocol that implements its own fragmentation and reassembly and aggressively ACKs or NACKs (negatively acknowledges) individual fragments. Lost fragments would be more quickly detected and retransmitted, and only the lost fragments would be retransmitted, not the whole message.
Synchronous versus Asynchronous Protocols
One way to characterize a protocol is by whether it is synchronous or
asynchronous. The precise meaning of these terms depends on where in
the protocol hierarchy you use them. At the transport layer, it is most
accurate to think of them as defining the extremes of a spectrum rather
than as two mutually exclusive alternatives. The key attribute of any
point along the spectrum is how much the sending process knows after the
operation to send a message returns. In other words, if we assume that
an application program invokes a send operation on a transport
protocol, then exactly what does the application know about the success
of the operation when the send operation returns?
At the asynchronous end of the spectrum, the application knows
absolutely nothing when send returns. Not only does it not know if
the message was received by its peer, but it doesn’t even know for sure
that the message has successfully left the local machine. At the
synchronous end of the spectrum, the send operation typically
returns a reply message. That is, the application not only knows that
the message it sent was received by its peer, but it also knows that the
peer has returned an answer. Thus, synchronous protocols implement the
request/reply abstraction, while asynchronous protocols are used if the
sender wants to be able to transmit many messages without having to wait
for a response. Using this definition, RPC protocols are usually
synchronous protocols.
Although we have not discussed them in this chapter, there are
interesting points between these two extremes. For example, the
transport protocol might implement send so that it blocks (does not
return) until the message has been successfully received at the remote
machine, but returns before the sender’s peer on that machine has
actually processed and responded to it. This is sometimes called a
reliable datagram protocol.
5.3.2 RPC Implementations (SunRPC, DCE, gRPC)
We now turn our discussion to some example implementations of RPC protocols. These will serve to highlight some of the different design decisions that protocol designers have made. Our first example is SunRPC, a widely used RPC protocol also known as Open Network Computing RPC (ONC RPC). Our second example, which we will refer to as DCE-RPC, is part of the Distributed Computing Environment (DCE). DCE is a set of standards and software for building distributed systems that was defined by the Open Software Foundation (OSF), a consortium of computer companies that originally included IBM, Digital Equipment Corporation, and Hewlett-Packard; today, OSF goes by the name The Open Group. Our third example is gRPC, a popular RPC mechanism that Google has open sourced, based on an RPC mechanism that they have been using internally to implement cloud services in their datacenters.
These three examples represent interesting alternative design choices in the RPC solution space, but lest you think they are the only options, we describe three other RPC-like mechanisms (WSDL, SOAP, and REST) in the context of web services in Chapter 9.
SunRPC
SunRPC became a de facto standard thanks to its wide distribution with Sun workstations and the central role it plays in Sun’s popular Network File System (NFS). The IETF subsequently adopted it as a standard Internet protocol under the name ONC RPC.
SunRPC can be implemented over several different transport protocols. Figure 141 illustrates the protocol graph when SunRPC is implemented on UDP. As we noted earlier in this section, a strict layerist might frown on the idea of running a transport protocol over a transport protocol, or argue that RPC must be something other than a transport protocol since it appears “above” the transport layer. Pragmatically, the design decision to run RPC over an existing transport layer makes quite a lot of sense, as will be apparent in the following discussion.
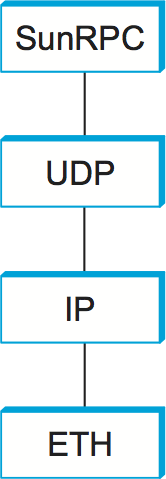
Figure 141. Protocol graph for SunRPC on top of UDP.
SunRPC uses two-tier identifiers to identify remote procedures: a
32-bit program number and a 32-bit procedure number. (There is also a
32-bit version number, but we ignore that in the following
discussion.) For example, the NFS server has been assigned program
number x00100003, and within this program getattr is procedure
1, setattr is procedure 2, read is procedure 6,
write is procedure 8, and so on. The program number and
procedure number are transmitted in the SunRPC request message’s
header, whose fields are shown in Figure 142. The server—which may support several program
numbers—is responsible for calling the specified procedure of the
specified program. A SunRPC request really represents a request to
call the specified program and procedure on the particular machine to
which the request was sent, even though the same program number may be
implemented on other machines in the same network. Thus, the address
of the server’s machine (e.g., an IP address) is an implicit third
tier of the RPC address.
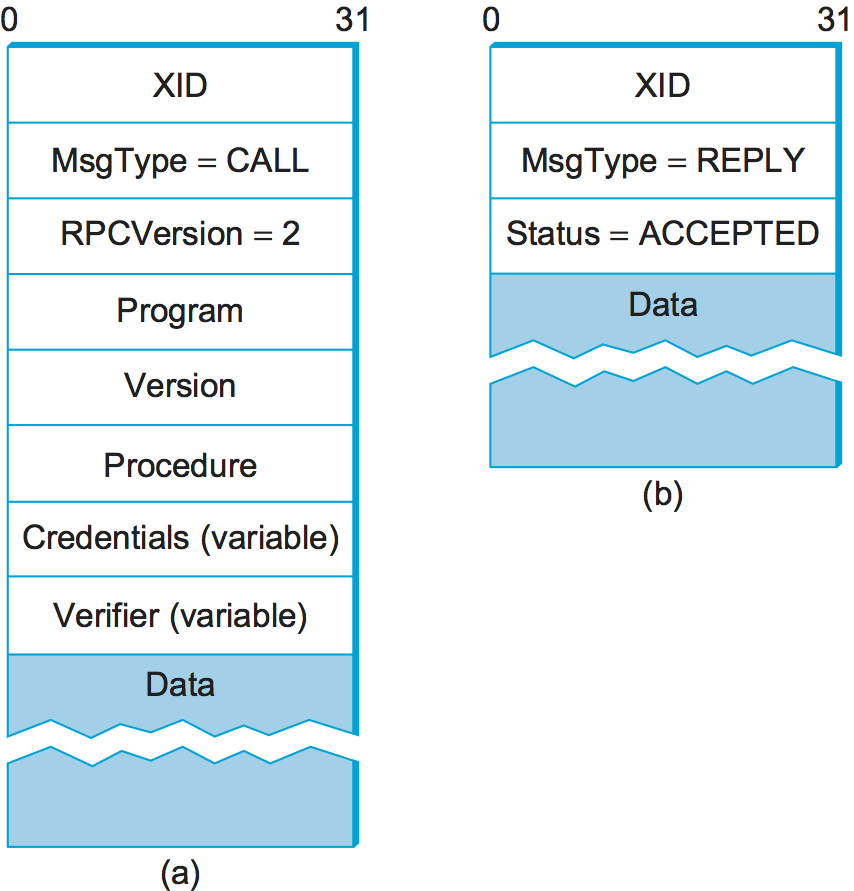
Figure 142. SunRPC header formats: (a) request; (b) reply.
Different program numbers may belong to different servers on the same
machine. These different servers have different transport layer demux
keys (e.g., UDP ports), most of which are not well-known numbers but
instead are assigned dynamically. These demux keys are called transport
selectors. How can a SunRPC client that wants to talk to a particular
program determine which transport selector to use to reach the
corresponding server? The solution is to assign a well-known address to
just one program on the remote machine and let that program handle the
task of telling clients which transport selector to use to reach any
other program on the machine. The original version of this SunRPC
program is called the Port Mapper, and it supports only UDP and TCP as
underlying protocols. Its program number is x00100000, and its
well-known port is 111. RPCBIND, which evolved from the Port Mapper,
supports arbitrary underlying transport protocols. As each SunRPC server
starts, it calls an RPCBIND registration procedure, on the server’s own
home machine, to register its transport selector and the program numbers
that it supports. A remote client can then call an RPCBIND lookup
procedure to look up the transport selector for a particular program
number.
To make this more concrete, consider an example using the Port Mapper
with UDP. To send a request message to NFS’s read procedure, a
client first sends a request message to the Port Mapper at well-known
UDP port 111, asking that procedure 3 be invoked to map
program number x00100003 to the UDP port where the NFS program
currently resides. The client then sends a SunRPC request message with
program number x00100003 and procedure number 6 to this UDP
port, and the SunRPC module listening at that port calls the NFS
read procedure. The client also caches the program-to-port number
mapping so that it need not go back to the Port Mapper each time it
wants to talk to the NFS program.1
- 1
In practice, NFS is such an important program that it has been given its own well-known UDP port, but for the purposes of illustration we’re pretending that’s not the case.
To match up a reply message with the corresponding request, so that
the result of the RPC can be returned to the correct caller, both
request and reply message headers include a XID (transaction ID)
field, as in Figure 142. A XID is a
unique transaction ID used only by one request and the corresponding
reply. After the server has successfully replied to a given request,
it does not remember the XID. Because of this, SunRPC cannot
guarantee at-most-once semantics.
The details of SunRPC’s semantics depend on the underlying transport protocol. It does not implement its own reliability, so it is only reliable if the underlying transport is reliable. (Of course, any application that runs over SunRPC may also choose to implement its own reliability mechanisms above the level of SunRPC.) The ability to send request and reply messages that are larger than the network MTU is also dependent on the underlying transport. In other words, SunRPC does not make any attempt to improve on the underlying transport when it comes to reliability and message size. Since SunRPC can run over many different transport protocols, this gives it considerable flexibility without complicating the design of the RPC protocol itself.
Returning to the SunRPC header format of Figure 142, the request message contains variable-length
Credentials and Verifier fields, both of which are used by the
client to authenticate itself to the server—that is, to give evidence
that the client has the right to invoke the server. How a client
authenticates itself to a server is a general issue that must be
addressed by any protocol that wants to provide a reasonable level of
security. This topic is discussed in more detail in another chapter.
DCE-RPC
DCE-RPC is the RPC protocol at the core of the DCE system and was the basis of the RPC mechanism underlying Microsoft’s DCOM and ActiveX. It can be used with the Network Data Representation (NDR) stub compiler described in another chapter, but it also serves as the underlying RPC protocol for the Common Object Request Broker Architecture (CORBA), which is an industry-wide standard for building distributed, object-oriented systems.
DCE-RPC, like SunRPC, can be implemented on top of several transport protocols including UDP and TCP. It is also similar to SunRPC in that it defines a two-level addressing scheme: the transport protocol demultiplexes to the correct server, DCE-RPC dispatches to a particular procedure exported by that server, and clients consult an “endpoint mapping service” (similar to SunRPC’s Port Mapper) to learn how to reach a particular server. Unlike SunRPC, however, DCE-RPC implements at-most-once call semantics. (In truth, DCE-RPC supports multiple call semantics, including an idempotent semantics similar to SunRPC’s, but at-most-once is the default behavior.) There are some other differences between the two approaches, which we will highlight in the following paragraphs.
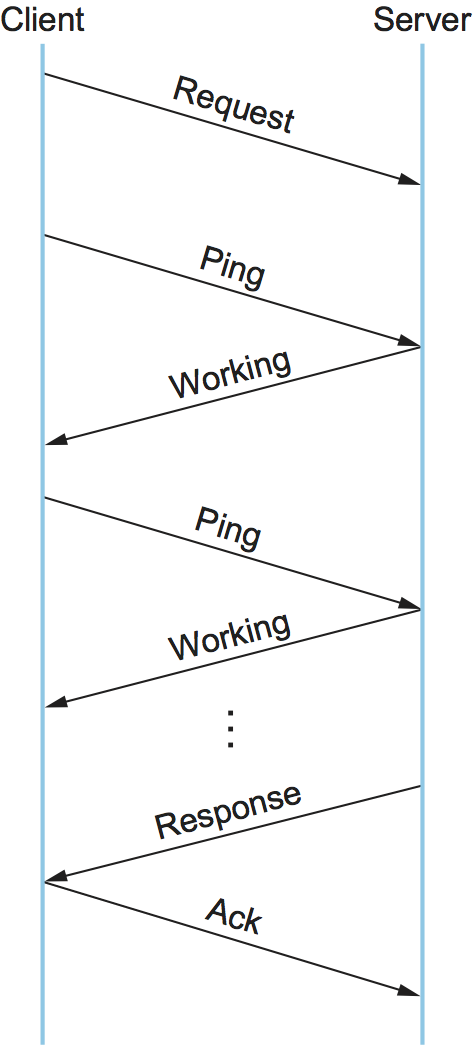
Figure 143. Typical DCE-RPC message exchange.
Figure 143 gives a timeline for the typical exchange of
messages, where each message is labeled by its DCE-RPC type. The client
sends a Request message, the server eventually replies with a
Response message, and the client acknowledges (Ack) the
response. Instead of the server acknowledging the request messages,
however, the client periodically sends a Ping message to the server,
which responds with a Working message to indicate that the remote
procedure is still in progress. If the server’s reply is received
reasonably quickly, no Pings are sent. Although not shown in the
figure, other message types are also supported. For example, the client
can send a Quit message to the server, asking it to abort an earlier
call that is still in progress; the server responds with a Quack
(quit acknowledgment) message. Also, the server can respond to a
Request message with a Reject message (indicating that a call
has been rejected), and it can respond to a Ping message with a
Nocall message (indicating that the server has never heard of the
caller).
Each request/reply transaction in DCE-RPC takes place in the context of
an activity. An activity is a logical request/reply channel between a
pair of participants. At any given time, there can be only one message
transaction active on a given channel. Like the concurrent logical
channel approach described above, the application programs have to open
multiple channels if they want to have more than one request/reply
transaction between them at the same time. The activity to which a
message belongs is identified by the message’s ActivityId field. A
SequenceNum field then distinguishes between calls made as part of
the same activity; it serves the same purpose as SunRPC’s XID
(transaction id) field. Unlike SunRPC, DCE-RPC keeps track of the last
sequence number used as part of a particular activity, so as to ensure
at-most-once semantics. To distinguish between replies sent before and
after a server machine reboots, DCE-RPC uses a ServerBoot field to
hold the machine’s boot ID.
Another design choice made in DCE-RPC that differs from SunRPC is the
support of fragmentation and reassembly in the RPC protocol. As noted
above, even if an underlying protocol such as IP provides
fragmentation/reassembly, a more sophisticated algorithm implemented as
part of RPC can result in quicker recovery and reduced bandwidth
consumption when fragments are lost. The FragmentNum field uniquely
identifies each fragment that makes up a given request or reply message.
Each DCE-RPC fragment is assigned a unique fragment number (0, 1, 2, 3,
and so on). Both the client and server implement a selective
acknowledgment mechanism, which works as follows. (We describe the
mechanism in terms of a client sending a fragmented request message to
the server; the same mechanism applies when a server sends a fragment
response to the client.)
First, each fragment that makes up the request message contains both a
unique FragmentNum and a flag indicating whether this packet is a
fragment of a call (frag) or the last fragment of a call (); request
messages that fit in a single packet carry a flag. The server knows it
has received the complete request message when it has the packet and
there are no gaps in the fragment numbers. Second, in response to each
arriving fragment, the server sends a Fack (fragment acknowledgment)
message to the client. This acknowledgment identifies the highest
fragment number that the server has successfully received. In other
words, the acknowledgment is cumulative, much like in TCP. In addition,
however, the server selectively acknowledges any higher fragment numbers
it has received out of order. It does so with a bit vector that
identifies these out-of-order fragments relative to the highest in-order
fragment it has received. Finally, the client responds by retransmitting
the missing fragments.
Figure 144 illustrates how this all works. Suppose
the server has successfully received fragments up through number 20,
plus fragments 23, 25, and 26. The server responds with a Fack
that identifies fragment 20 as the highest in-order fragment, plus a
bit-vector (SelAck) with the third (23=20+3), fifth (25=20+5), and
sixth (26=20+6) bits turned on. So as to support an (almost)
arbitrarily long bit vector, the size of the vector (measured in
32-bit words) is given in the SelAckLen field.

Figure 144. Fragmentation with selective acknowledgments.
Given DCE-RPC’s support for very large messages—the FragmentNum
field is 16 bits long, meaning it can support 64K fragments—it is not
appropriate for the protocol to blast all the fragments that make up a
message as fast as it can since doing so might overrun the receiver.
Instead, DCE-RPC implements a flow-control algorithm that is very
similar to TCP’s. Specifically, each Fack message not only
acknowledges received fragments but also informs the sender of how
many fragments it may now send. This is the purpose of the
WindowSize field in Figure 144, which serves
exactly the same purpose as TCP’s AdvertisedWindow field except it
counts fragments rather than bytes. DCE-RPC also implements a
congestion-control mechanism that is similar to TCP’s. Given the
complexity of congestion control, it is perhaps not surprising that
some RPC protocols avoid it by avoiding fragmentation.
In summary, designers have quite a range of options open to them when designing an RPC protocol. SunRPC takes the more minimalist approach and adds relatively little to the underlying transport beyond the essentials of locating the right procedure and identifying messages. DCE-RPC adds more functionality, with the possibility of improved performance in some environments at the cost of greater complexity.
gRPC
Despite its origins in Google, gRPC does not stand for Google RPC. The “g” stands for something different in each release. For version 1.10 it stood for “glamorous” and for 1.18 it stood for “goose”. According to the official gRPC FAQ, it is now a recursive acronym: gRPC means “gRPC Remote Procedure Call”. Googlers are wild and crazy people. Nonetheless, gRPC is popular because it makes available to everyone—as open source—a decade’s worth of experience within Google using RPC to build scalable cloud services.
Before getting into the details, there are some major differences between gRPC and the other two examples we’ve just covered. The biggest is that gRPC is designed for cloud services rather than the simpler client/server paradigm that preceded it. The difference is essentially an extra level of indirection. In the client/server world, the client invokes a method on a specific server process running on a specific server machine. One server process is presumed to be enough to serve calls from all the client processes that might call it.
With cloud services, the client invokes a method on a service, which in order to support calls from arbitrarily many clients at the same time, is implemented by a scalable number of server processes, each potentially running on a different server machine. This is where the cloud comes into play: datacenters make a seemingly infinite number of server machines available to scale up cloud services. When we use the term “scalable” we mean that the number of identical server processes you elect to create depends on the workload (i.e., the number of clients that want service at any given time) and that number can be adjusted dynamically over time. One other detail is that cloud services don’t typically create a new process, per se, but rather, they launch a new container, which is essentially a process encapsulated inside an isolated environment that includes all the software packages the process needs to run. Docker is today’s canonical example of a container platform.
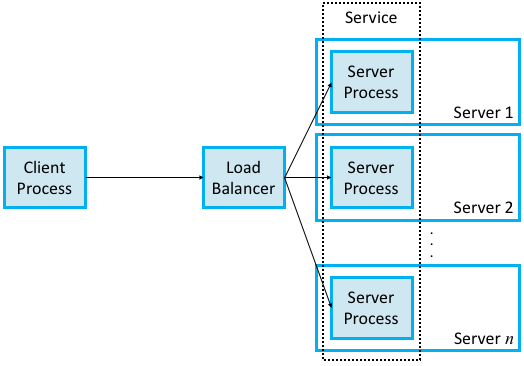
Figure 145. Using RPC to invoke a scalable cloud service.
Back to the claim that a service is essentially an extra level of indirection layered on top of a server, all this means is that the caller identifies the service it wants to invoke, and a load balancer directs that invocation to one of the many available server processes (containers) that implement that service, as shown in Figure 145. The load balancer can be implemented in different ways, including a hardware device, but it is typically implemented by a proxy process that runs in a virtual machine (also hosted in the cloud) rather than as a physical appliance.
There is a set of best practices for implementing the actual server code that eventually responds to that request, and some additional cloud machinery to create/destroy containers and load balance requests across those containers. Kubernetes is today’s canonical example of such a container management system, and the micro-services architecture is what we call the best practices in building services in this cloud native manner. Both are interesting topics, but beyond the scope of this book.
What we are interested in here is transport protocol at the core of gRPC. Here again, there is a major departure from the two previous example protocols, not in terms of fundamental problems that need to be addressed, but in terms of gRPC’s approach to addressing them. In short, gRPC “outsources” many of the problems to other protocols, leaving gRPC to essentially package those capabilities in an easy-to-use form. Let’s look at the details.
First, gRPC runs on top of TCP instead of UDP, which means it outsources the problems of connection management and reliably transmitting request and reply messages of arbitrary size. Second, gRPC actually runs on top of a secured version of TCP called Transport Layer Security (TLS)—a thin layer that sits above TCP in the protocol stack—which means it outsources responsibility for securing the communication channel so adversaries can’t eavesdrop or hijack the message exchange. Third, gRPC actually, actually runs on top of HTTP/2 (which is itself layered on top of TCP and TLS), meaning gRPC outsources yet two other problems: (1) efficiently encoding/compressing binary data into a message, (2) multiplexing multiple remote procedure calls onto a single TCP connection. In other words, gRPC encodes the identifier for the remote method as a URI, the request parameters to the remote method as content in the HTTP message, and the return value from the remote method in the HTTP response. The full gRPC stack is depicted in Figure 146, which also includes the language-specific elements. (One strength of gRPC is the wide set of programming languages it supports, with only a small subset shown in Figure 146.)
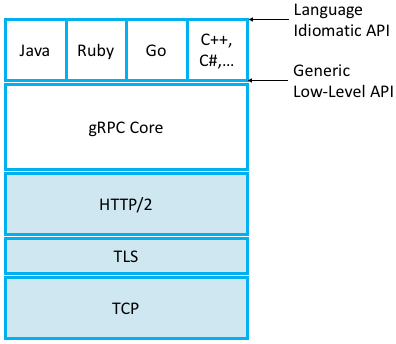
Figure 146. gRPC core stacked on top of HTTP, TLS, and TCP and supporting a collection of languages.
We discuss TLS in Chapter 8 (in the context of a broad range of security topics) and HTTP in Chapter 9 (in the context of what are traditionally viewed as application level protocols). But we find ourselves in an interesting dependency loop: RPC is a flavor of transport protocol used to implement distributed applications, HTTP is an example of an application-level protocol, and yet gRPC runs on top of HTTP rather than the other way around.
The short explanation is that layering provides a convenient way for humans to wrap their heads around complex systems, but what we’re really trying to do is solve a set of problem (e.g., reliably transfer messages of arbitrary size, identify senders and recipients, match requests messages with reply messages, and so on) and the way these solutions get bundled into protocols, and those protocols then layered on top of each other, is the consequence of incremental changes over time. You could argue it’s an historical accident. Had the Internet started with an RPC mechanism as ubiquitous as TCP, HTTP might have been implemented on top of it (as might have almost all of the other application-level protocols described in Chapter 9) and Google would have spent their time improving that protocol rather than inventing one of their own (as they and others have been doing with TCP). What happened instead is that the web became the Internet’s killer app, which meant that its application protocol (HTTP) became universally supported by the rest of the Internet’s infrastructure: Firewalls, Load Balancers, Encryption, Authentication, Compression, and so on. Because all of these network elements have been designed to work well with HTTP, HTTP has effectively become the Internet’s universal request/reply transport protocol.
Returning to the unique characteristics of gRPC, the biggest value it brings to the table is to incorporate streaming into the RPC mechanism, which is to say, gRPC supports four different request/reply patterns:
Simple RPC: The client sends a single request message and the server responds with a single reply message.
Server Streaming RPC: The client sends a single request message and the server responds with a stream of reply messages. The client completes once it has all the server’s responses.
Client Streaming RPC: The client sends a stream of requests to the server, and the server sends back a single response, typically (but not necessarily) after it has received all the client’s requests.
Bidirectional Streaming RPC: The call is initiated by the client, but after that, the client and server can read and write requests and responses in any order; the streams are completely independent.
This extra freedom in how the client and server interact means the gRPC
transport protocol needs to send additional metadata and control
messages—in addition to the actual request and reply messages—between
the two peers. Examples include Error and Status codes (to
indicate success or why something failed), Timeouts (to indicate how
long a client is willing to wait for a response), PING (a keep-alive
notice to indicate that one side or the other is still running), EOS
(end-of-stream notice to indicate that there are no more requests or
responses), and GOAWAY (a notice from servers to clients to indicate
that they will no longer accept any new streams). Unlike many other
protocols in this book, where we show the protocol’s header format, the
way this control information gets passed between the two sides is
largely dictated by the underlying transport protocol, in this case
HTTP/2. For example, as we’ll see in Chapter 9, HTTP already includes a
set of header fields and reply codes that gRPC takes advantage of.
You may want to peruse the HTTP discussion in Chapter 9 before continuing, but the following is fairly straightforward. A simple RPC request (with no streaming) might include the following HTTP message from the client to the server:
HEADERS (flags = END_HEADERS)
:method = POST
:scheme = http
:path = /google.pubsub.v2.PublisherService/CreateTopic
:authority = pubsub.googleapis.com
grpc-timeout = 1S
content-type = application/grpc+proto
grpc-encoding = gzip
authorization = Bearer y235.wef315yfh138vh31hv93hv8h3v
DATA (flags = END_STREAM)
<Length-Prefixed Message>
leading to the following response message from the server back to the client:
HEADERS (flags = END_HEADERS)
:status = 200
grpc-encoding = gzip
content-type = application/grpc+proto
DATA
<Length-Prefixed Message>
HEADERS (flags = END_STREAM, END_HEADERS)
grpc-status = 0 # OK
trace-proto-bin = jher831yy13JHy3hc
In this example, HEADERS and DATA are two standard HTTP
control messages, which effectively delineate between “the message’s
header” and “the message’s payload.” Specifically, each line following
HEADERS (but before DATA) is an attribute = value pair
that makes up the header (think of each line as analogous to a header
field); those pairs that start with colon (e.g., :status = 200)
are part of the HTTP standard (e.g., status 200 indicates
success); and those pairs that do not start with a colon are
gRPC-specific customizations (e.g., grpc-encoding = gzip indicates
that the data in the message that follows has been compressed using
gzip, and grpc-timeout = 1S indicates that the client has set
a one second timeout).
There is one final piece to explain. The header line
content-type = application/grpc+proto
indicates that the message body (as demarcated by the DATA line)
is meaningful only to the application program (i.e., the server
method) that this client is requesting service from. More
specifically, the +proto string specifies that the recipient will
be able to interpret the bits in the message according to a Protocol
Buffer (abbreviated proto) interface specification. Protocol
Buffers are gRPC’s way of specifying how the parameters being passed
to the server are encoded into a message, which is in turn used to
generate the stubs that sit between the underlying RPC mechanism and
the actual functions being called (see Figure 138). This is a topic we’ll take up in Chapter 7.
Key Takeaway
The bottom line is that complex mechanisms like RPC, once packaged as a monolithic bundle of software (as with SunRPC and DCE-RPC), is nowadays built by assembling an assortment of smaller pieces, each of which solves a narrow problem. gRPC is both an example of that approach, and a tool that enables further adoption of the approach. The micro-services architecture mentioned earlier in this subsection applies the “built from small parts” strategy to entire cloud applications (e.g., Uber, Lyft, Netflix, Yelp, Spotify), where gRPC is often the communication mechanism used by those small pieces to exchange messages with each other. [Next]