3.2 Switched Ethernet
Having discussed some of the basic ideas behind switching, we now focus more closely on a specific switching technology: Switched Ethernet. The switches used to build such networks, which are often referred to as L2 switches, are widely used in campus and enterprise networks. Historically, they were more commonly referred to as bridges because they were used to “bridge” ethernet segments to build an extended LAN. But today most networks deploy Ethernet in a point-to-point configuration, with these links interconnected by L2 switches to form a switched Ethernet.
The following starts with the historical perspective (using bridges to connect a set of Ethernet segments), and then shifts to the perspective in wide-spread use today (using L2 switches to connect a set of point-to-point links). But whether we call the device a bridge or a switch—and the network you build an extended LAN or a switched Ethernet—the two behave in exactly the same way.
To begin, suppose you have a pair of Ethernets that you want to interconnect. One approach you might try is to put a repeater between them. This would not be a workable solution, however, if doing so exceeded the physical limitations of the Ethernet. (Recall that no more than four repeaters between any pair of hosts and no more than a total of 2500 m in length are allowed.) An alternative would be to put a node with a pair of Ethernet adaptors between the two Ethernets and have the node forward frames from one Ethernet to the other. This node would differ from a repeater, which operates on bits, not frames, and just blindly copies the bits received on one interface to another. Instead, this node would fully implement the Ethernet’s collision detection and media access protocols on each interface. Hence, the length and number-of-host restrictions of the Ethernet, which are all about managing collisions, would not apply to the combined pair of Ethernets connected in this way. This device operates in promiscuous mode, accepting all frames transmitted on either of the Ethernets, and forwarding them to the other.
In their simplest variants, bridges simply accept LAN frames on their inputs and forward them out on all other outputs. This simple strategy was used by early bridges but has some pretty serious limitations as we’ll see below. A number of refinements were added over the years to make bridges an effective mechanism for interconnecting a set of LANs. The rest of this section fills in the more interesting details.
3.2.1 Learning Bridges
The first optimization we can make to a bridge is to observe that it need not forward all frames that it receives. Consider the bridge in Figure 64. Whenever a frame from host A that is addressed to host B arrives on port 1, there is no need for the bridge to forward the frame out over port 2. The question, then, is how does a bridge come to learn on which port the various hosts reside?
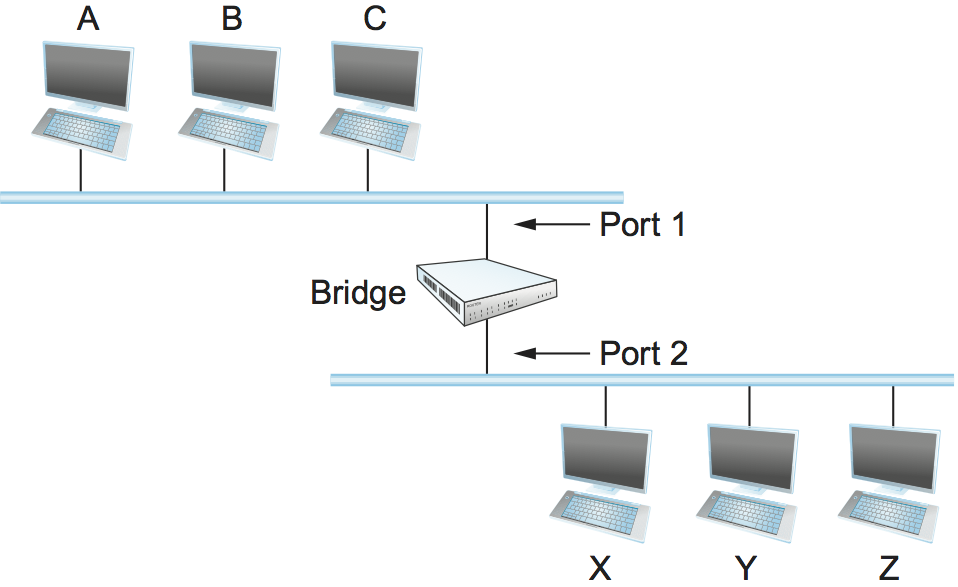
Figure 64. Illustration of a learning bridge.
One option would be to have a human download a table into the bridge similar to the one given in Table 9. Then, whenever the bridge receives a frame on port 1 that is addressed to host A, it would not forward the frame out on port 2; there would be no need because host A would have already directly received the frame on the LAN connected to port 1. Anytime a frame addressed to host A was received on port 2, the bridge would forward the frame out on port 1.
Host |
Port |
|---|---|
A |
1 |
B |
1 |
C |
1 |
X |
2 |
Y |
2 |
Z |
2 |
Having a human maintain this table is too burdensome, and there is a simple trick by which a bridge can learn this information for itself. The idea is for each bridge to inspect the source address in all the frames it receives. Thus, when host A sends a frame to a host on either side of the bridge, the bridge receives this frame and records the fact that a frame from host A was just received on port 1. In this way, the bridge can build a table just like Table 9.
Note that a bridge using such a table implements a version of the datagram (or connectionless) model of forwarding described earlier. Each packet carries a global address, and the bridge decides which output to send a packet on by looking up that address in a table.
When a bridge first boots, this table is empty; entries are added over time. Also, a timeout is associated with each entry, and the bridge discards the entry after a specified period of time. This is to protect against the situation in which a host—and, as a consequence, its LAN address—is moved from one network to another. Thus, this table is not necessarily complete. Should the bridge receive a frame that is addressed to a host not currently in the table, it goes ahead and forwards the frame out on all the other ports. In other words, this table is simply an optimization that filters out some frames; it is not required for correctness.
3.2.2 Implementation
The code that implements the learning bridge algorithm is quite
simple, and we sketch it here. Structure BridgeEntry defines a
single entry in the bridge’s forwarding table; these are stored in a
Map structure (which supports mapCreate, mapBind, and
mapResolve operations) to enable entries to be efficiently located
when packets arrive from sources already in the table. The constant
MAX_TTL specifies how long an entry is kept in the table before it
is discarded.
#define BRIDGE_TAB_SIZE 1024 /* max size of bridging table */
#define MAX_TTL 120 /* time (in seconds) before an entry is flushed */
typedef struct {
MacAddr destination; /* MAC address of a node */
int ifnumber; /* interface to reach it */
u_short TTL; /* time to live */
Binding binding; /* binding in the Map */
} BridgeEntry;
int numEntries = 0;
Map bridgeMap = mapCreate(BRIDGE_TAB_SIZE, sizeof(BridgeEntry));
The routine that updates the forwarding table when a new packet arrives
is given by updateTable. The arguments passed are the source media
access control (MAC) address contained in the packet and the interface
number on which it was received. Another routine, not shown here, is
invoked at regular intervals, scans the entries in the forwarding table,
and decrements the TTL (time to live) field of each entry,
discarding any entries whose TTL has reached 0. Note that the
TTL is reset to MAX_TTL every time a packet arrives to refresh
an existing table entry and that the interface on which the destination
can be reached is updated to reflect the most recently received packet.
void
updateTable (MacAddr src, int inif)
{
BridgeEntry *b;
if (mapResolve(bridgeMap, &src, (void **)&b) == FALSE )
{
/* this address is not in the table, so try to add it */
if (numEntries < BRIDGE_TAB_SIZE)
{
b = NEW(BridgeEntry);
b->binding = mapBind( bridgeMap, &src, b);
/* use source address of packet as dest. address in table */
b->destination = src;
numEntries++;
}
else
{
/* can't fit this address in the table now, so give up */
return;
}
}
/* reset TTL and use most recent input interface */
b->TTL = MAX_TTL;
b->ifnumber = inif;
}
Note that this implementation adopts a simple strategy in the case where the bridge table has become full to capacity—it simply fails to add the new address. Recall that completeness of the bridge table is not necessary for correct forwarding; it just optimizes performance. If there is some entry in the table that is not currently being used, it will eventually time out and be removed, creating space for a new entry. An alternative approach would be to invoke some sort of cache replacement algorithm on finding the table full; for example, we might locate and remove the entry with the smallest TTL to accommodate the new entry.
3.2.3 Spanning Tree Algorithm
The preceding strategy works just fine until the network has a loop in it, in which case it fails in a horrible way—frames potentially get forwarded forever. This is easy to see in the example depicted in Figure 65, where switches S1, S4, and S6 form a loop.
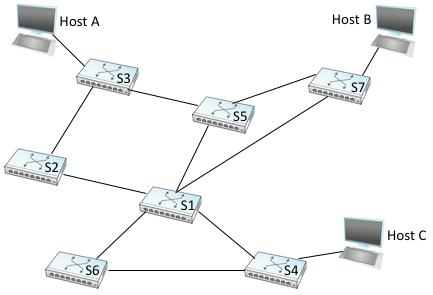
Figure 65. Switched Ethernet with loops.
Note that we are now making the shift from calling the each forwarding device a bridge (connecting segments that might reach multiple other devices) to instead calling them L2 switches (connecting point-to-point links that reach just one other device). To keep the example manageable, we include just three hosts. In practice, switches typically have 16, 24, or 48 ports, meaning they are able to connect to that many hosts (and other switches).
In our example switched network, suppose that a packet enters switch S4 from Host C and that the destination address is one not yet in any switch’s forwarding table: S4 sends a copy of the packet out its two other ports: to switches S1 and S6. Switch S6 forwards the packet onto S1 (and meanwhile, S1 forwards the packet onto S6), both of which in turn forward their packets back to S4. Switch S4 still doesn’t have this destination in its table, so it forwards the packet out its two other ports. There is nothing to stop this cycle from repeating endlessly, with packets looping in both directions among S1, S4, and S6.
Why would a switched Ethernet (or extended LAN) come to have a loop in it? One possibility is that the network is managed by more than one administrator, for example, because it spans multiple departments in an organization. In such a setting, it is possible that no single person knows the entire configuration of the network, meaning that a switch that closes a loop might be added without anyone knowing. A second, more likely scenario is that loops are built into the network on purpose—to provide redundancy in case of failure. After all, a network with no loops needs only one link failure to become split into two separate partitions.
Whatever the cause, switches must be able to correctly handle loops. This problem is addressed by having the switches run a distributed spanning tree algorithm. If you think of the network as being represented by a graph that possibly has loops (cycles), then a spanning tree is a subgraph of this graph that covers (spans) all the vertices but contains no cycles. That is, a spanning tree keeps all of the vertices of the original graph but throws out some of the edges. For example, Figure 66 shows a cyclic graph on the left and one of possibly many spanning trees on the right.
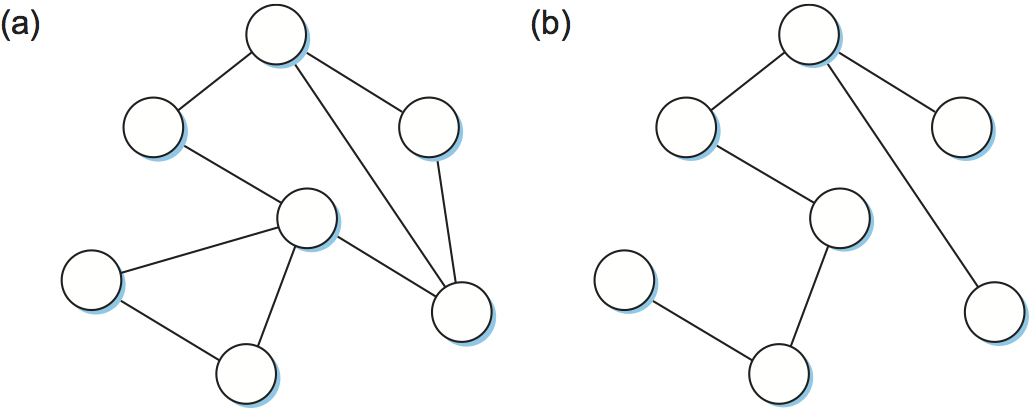
Figure 66. Example of (a) a cyclic graph; (b) a corresponding spanning tree.
The idea of a spanning tree is simple enough: It’s a subset of the actual network topology that has no loops and that reaches all the devices in the network. The hard part is how all of the switches coordinate their decisions to arrive at a single view of the spanning tree. After all, one topology is typically able to be covered by multiple spanning trees. The answer lies in the spanning tree protocol, which we’ll describe now.
The spanning tree algorithm, which was developed by Radia Perlman, then at the Digital Equipment Corporation, is a protocol used by a set of switches to agree upon a spanning tree for a particular network. (The IEEE 802.1 specification is based on this algorithm.) In practice, this means that each switch decides the ports over which it is and is not willing to forward frames. In a sense, it is by removing ports from the topology that the network is reduced to an acyclic tree. It is even possible that an entire switch will not participate in forwarding frames, which seems kind of strange at first glance. The algorithm is dynamic, however, meaning that the switches are always prepared to reconfigure themselves into a new spanning tree should some switch fail, and so those unused ports and switches provide the redundant capacity needed to recover from failures.
The main idea of the spanning tree is for the switches to select the ports over which they will forward frames. The algorithm selects ports as follows. Each switch has a unique identifier; for our purposes, we use the labels S1, S2, S3, and so on. The algorithm first elects the switch with the smallest ID as the root of the spanning tree; exactly how this election takes place is described below. The root switch always forwards frames out over all of its ports. Next, each switch computes the shortest path to the root and notes which of its ports is on this path. This port is also selected as the switch’s preferred path to the root. Finally, to account for the possibility there could be another switch connected to its ports, the switch elects a single designated switch that will be responsible for forwarding frames toward the root. Each designated switch is the one that is closest to the root. If two or more switches are equally close to the root, then the switches’ identifiers are used to break ties, and the smallest ID wins. Of course, each switch might be connected to more than one other switch, so it participates in the election of a designated switch for each such port. In effect, this means that each switch decides if it is the designated switch relative to each of its ports. The switch forwards frames over those ports for which it is the designated switch.
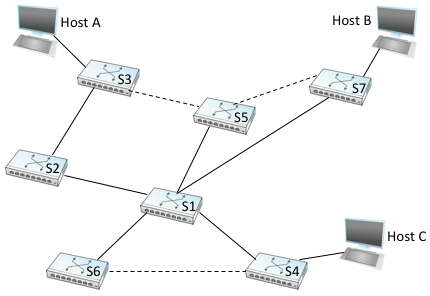
Figure 67. Spanning tree with some ports not selected.
Figure 67 shows the spanning tree that corresponds to the network shown in Figure 65. In this example, S1 is the root, since it has the smallest ID. Notice that S3 and S5 are connected to each other, but S5 is the designated switch since it is closer to the root. Similarly, S5 and S7 are connected to each other, but in this case S5 is the designated switch since it has the smaller ID; both are an equal distance from S1.
While it is possible for a human to look at the network given in Figure 65 and to compute the spanning tree given in the Figure 67 according to the rules given above, the switches do not have the luxury of being able to see the topology of the entire network, let alone peek inside other switches to see their ID. Instead, they have to exchange configuration messages with each other and then decide whether or not they are the root or a designated switch based on these messages.
Specifically, the configuration messages contain three pieces of information:
The ID for the switch that is sending the message.
The ID for what the sending switch believes to be the root switch.
The distance, measured in hops, from the sending switch to the root switch.
Each switch records the current best configuration message it has seen on each of its ports (“best” is defined below), including both messages it has received from other switches and messages that it has itself transmitted.
Initially, each switch thinks it is the root, and so it sends a configuration message out on each of its ports identifying itself as the root and giving a distance to the root of 0. Upon receiving a configuration message over a particular port, the switch checks to see if that new message is better than the current best configuration message recorded for that port. The new configuration message is considered better than the currently recorded information if any of the following is true:
It identifies a root with a smaller ID.
It identifies a root with an equal ID but with a shorter distance.
The root ID and distance are equal, but the sending switch has a smaller ID
If the new message is better than the currently recorded information, the switch discards the old information and saves the new information. However, it first adds 1 to the distance-to-root field since the switch is one hop farther away from the root than the switch that sent the message.
When a switch receives a configuration message indicating that it is not the root—that is, a message from a switch with a smaller ID—the switch stops generating configuration messages on its own and instead only forwards configuration messages from other switches, after first adding 1 to the distance field. Likewise, when a switch receives a configuration message that indicates it is not the designated switch for that port—that is, a message from a switch that is closer to the root or equally far from the root but with a smaller ID—the switch stops sending configuration messages over that port. Thus, when the system stabilizes, only the root switch is still generating configuration messages, and the other switches are forwarding these messages only over ports for which they are the designated switch. At this point, a spanning tree has been built, and all the switches are in agreement on which ports are in use for the spanning tree. Only those ports may be used for forwarding data packets.
Let’s see how this works with an example. Consider what would happen in Figure 67 if the power had just been restored to a campus, so that all the switches boot at about the same time. All the switches would start off by claiming to be the root. We denote a configuration message from node X in which it claims to be distance d from root node Y as (Y,d,X). Focusing on the activity at S3, a sequence of events would unfold as follows:
S3 receives (S2, 0, S2).
Since 2 < 3, S3 accepts S2 as root.
S3 adds one to the distance advertised by S2 (0) and thus sends (S2, 1, S3) toward S5.
Meanwhile, S2 accepts S1 as root because it has the lower ID, and it sends (S1, 1, S2) toward S3.
S5 accepts S1 as root and sends (S1, 1, S5) toward S3.
S3 accepts S1 as root, and it notes that both S2 and S5 are closer to the root than it is, but S2 has the smaller id, so it remains on S3’s path to the root.
This leaves S3 with active ports as shown in Figure 67. Note that Hosts A and B are not able to communicate over the shortest path (via S5) because frames have to “flow up the tree and back down,” but that’s the price you pay to avoid loops.
Even after the system has stabilized, the root switch continues to send configuration messages periodically, and the other switches continue to forward these messages as just described. Should a particular switch fail, the downstream switches will not receive these configuration messages, and after waiting a specified period of time they will once again claim to be the root, and the algorithm will kick in again to elect a new root and new designated switches.
One important thing to notice is that although the algorithm is able to reconfigure the spanning tree whenever a switch fails, it is not able to forward frames over alternative paths for the sake of routing around a congested switch.
3.2.4 Broadcast and Multicast
The preceding discussion focuses on how switches forward unicast frames from one port to another. Since the goal of a switch is to transparently extend a LAN across multiple networks, and since most LANs support both broadcast and multicast, then switches must also support these two features. Broadcast is simple—each switch forwards a frame with a destination broadcast address out on each active (selected) port other than the one on which the frame was received.
Multicast can be implemented in exactly the same way, with each host deciding for itself whether or not to accept the message. This is exactly what is done in practice. Notice, however, that since not all hosts are a member of any particular multicast group, it is possible to do better. Specifically, the spanning tree algorithm can be extended to prune networks over which multicast frames need not be forwarded. Consider a frame sent to group M by a host A in Figure 67. If host C does not belong to group M, then there is no need for switch S4 to forward the frames over that network.
How would a given switch learn whether it should forward a multicast frame over a given port? It learns exactly the same way that a switch learns whether it should forward a unicast frame over a particular port—by observing the source addresses that it receives over that port. Of course, groups are not typically the source of frames, so we have to cheat a little. In particular, each host that is a member of group M must periodically send a frame with the address for group M in the source field of the frame header. This frame would have as its destination address the multicast address for the switches.
Although the multicast extension just described was once proposed, it was not widely adopted. Instead, multicast is implemented in exactly the same way as broadcast.
3.2.5 Virtual LANs (VLANs)
One limitation of switches is that they do not scale. It is not realistic to connect more than a few switches, where in practice few typically means “tens of.” One reason for this is that the spanning tree algorithm scales linearly; that is, there is no provision for imposing a hierarchy on the set of switches. A second reason is that switches forward all broadcast frames. While it is reasonable for all hosts within a limited setting (say, a department) to see each other’s broadcast messages, it is unlikely that all the hosts in a larger environment (say, a large company or university) would want to have to be bothered by each other’s broadcast messages. Said another way, broadcast does not scale, and as a consequence L2-based networks do not scale.
One approach to increasing the scalability is the virtual LAN (VLAN). VLANs allow a single extended LAN to be partitioned into several seemingly separate LANs. Each virtual LAN is assigned an identifier (sometimes called a color), and packets can only travel from one segment to another if both segments have the same identifier. This has the effect of limiting the number of segments in an extended LAN that will receive any given broadcast packet.
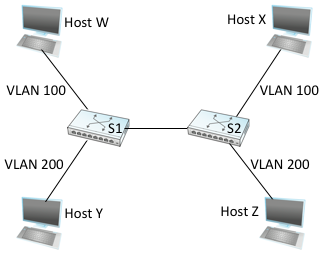
Figure 68. Two virtual LANs share a common backbone.
We can see how VLANs work with an example. Figure 68 shows four hosts and two switches. In the absence of VLANs, any broadcast packet from any host will reach all the other hosts. Now let’s suppose that we define the segments connected to hosts W and X as being in one VLAN, which we’ll call VLAN 100. We also define the segments that connect to hosts Y and Z as being in VLAN 200. To do this, we need to configure a VLAN ID on each port of switches S1 and S2. The link between S1 and S2 is considered to be in both VLANs.
When a packet sent by host X arrives at switch S2, the switch observes that it came in a port that was configured as being in VLAN 100. It inserts a VLAN header between the Ethernet header and its payload. The interesting part of the VLAN header is the VLAN ID; in this case, that ID is set to 100. The switch now applies its normal rules for forwarding to the packet, with the extra restriction that the packet may not be sent out an interface that is not part of VLAN 100. Thus, under no circumstances will the packet—even a broadcast packet—be sent out the interface to host Z, which is in VLAN 200. The packet, however, is forwarded on to switch S1, which follows the same rules and thus may forward the packet to host W but not to host Y.
An attractive feature of VLANs is that it is possible to change the logical topology without moving any wires or changing any addresses. For example, if we wanted to make the link that connects to host Z be part of VLAN 100 and thus enable X, W, and Z to be on the same virtual LAN, then we would just need to change one piece of configuration on switch S2.
Supporting VLANs requires a fairly simple extension to the
original 802.1 header specification, inserting a 12-bit VLAN ID
(VID) field between the SrcAddr and Type fields, as shown in
Figure 69. (This VID is typically referred to as
a VLAN Tag.) There are actually 32-bits inserted in the middle of
the header, but the first 16-bits are used to preserve backwards
compatibility with the original specification (they use Type =
0x8100 to indicate that this frame includes the VLAN extension); the
other four bits hold control information used to prioritize
frames. This means it is possible to map \(2^{12} = 4096\) virtual
networks onto a single physical LAN.
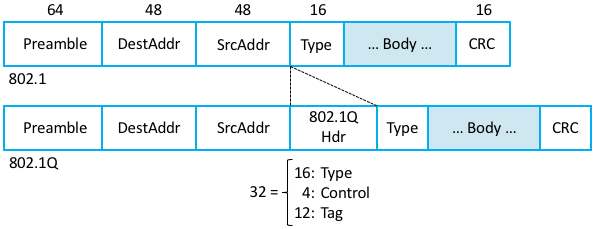
Figure 69. 802.1Q VLAN tag embedded within an Ethernet (802.1) header.
We conclude this discussion by observing there is another limitation of networks built by interconnecting L2 switches: lack of support for heterogeneity. That is, switches are limited in the kinds of networks they can interconnect. In particular, switches make use of the network’s frame header and so can support only networks that have exactly the same format for addresses. For example, switches can be used to connect Ethernet and 802.11-based networks to each other, since they share a common header format, but switches do not readily generalize to other kinds of networks with different addressing formats, such as ATM, SONET, PON, or the cellular network. The next section explains how to address this limitation, as well as to scale switched networks to even larger sizes.